Programma AlphaGo verslaat Go-prof Fan Hui (2p)
Nog geen twintig jaar geleden versloeg programma Deep Blue van IBM voor het eerst regerend wereldkampioen schaken Gari Kasparov. In een match over zes partijen met standaard tournooi bedenktijd won Deep Blue met 3.5 – 2.5. Kasparov beschuldigde IBM van vals spel en eiste per direkt een herkansingsmatch. IBM weigerde en Deep Blue ging voorgoed met pensioen.
Nog geen twintig jaar geleden versloeg programma Deep Blue van IBM voor het eerst regerend wereldkampioen schaken Gari Kasparov. In een match over zes partijen met standaard tournooi bedenktijd won Deep Blue met 3.5 – 2.5. Kasparov beschuldigde IBM van vals spel en eiste per direkt een herkansingsmatch. IBM weigerde en Deep Blue ging voorgoed met pensioen.
Deze week ging baanbrekend nieuws de hele wereld over: programma AlphaGo van DeepMind wint vijf partijen match tegen regerend Europees kampioen Fan Hui (2p). Niet eerder versloeg een computer programma een Go-prof met 5-0 in formele partijen zonder handicap en 1h normale bedenktijd (3x30s byoyomi, 19x19, 7.5 komi, chinese regels). De tot nu toe meest uitdagende en complexe klus, voor computers en kunstmatige intelligentie wereldwijd, lijkt dus te zijn geklaard. Dat zou een enorme mijlpaal in de geschiedenis betekenen.
De match vond overigens al 5-9 Oktober 2015 plaats, achter gesloten deuren in het Google DeepMind kantoor in Londen. Pas na de recente onderzoekspublicatie over de werking van het programma kwamen alle details naar buiten. Zo werden speelvoorwaarden en bedenktijd door Fan Hui zelf gekozen, voorafgaand aan de match. Een onafhankelijke arbiter beoordeelde de geldigheid van zetten en het verloop van de partij. En er werd afgesproken dat de algehele match uitslag uitsluitend bepaald zou worden door de formele partijen (inclusief informele partijen zou het 8-2 geweest zijn in het voordeel van AlphaGo).
Wie had er in 1985 gedacht, toen Ronald Schlemper de centrale jeugdtraining stevig op poten zette, dat ruim 30 jaar later een programma gelijk-op tegen een 2d prof zou kunnen winnen? Of in 1987, toen Robert Rehm en Peter Zandveld een weddenschap aangingen (om 2000 gulden) of er in het jaar 2000 een programma met negen stenen voor van Robert (5d) zou kunnen winnen? Robert won makkelijk van HandTalk (maker Chen, Zhixing), destijds één van de sterkste programma's ter wereld, en stelde dat het nóg een stuk makkelijker zou zijn geweest als HandTalk 25 stenen voorgift had gehad. Of in 1989, toen Mark Boon voor het eerst wereldkampioen computer Go werd en een educatief Go-programma héél trots mocht zijn als het van een 10e kyu amateur kon winnen?
De opzienbare doorbraak van AlphaGo komt slechts een paar jaar nadat Takemiya Masaki (9p) werd verslagen in een 4 stenen handicap game door programma Zen (in 2012). En Yoshio Ishida (9p) door programma Crazy Stone (in 2013, ook met 4 stenen handicap). Nu AlphaGo minstens even sterk speelt als de van oorsprong chinese prof Fan Hui --die Go leerde op zijn 7e, al op zijn 16e jaar 1d professional werd en al ruim 25 jaar Go ademt en leeft-- is de vraag: 'Moeten we ons neerleggen bij 't feit dat kunstmatige intelligentie Go onder de knie begint te krijgen?'.
Is dan nu de tijd echt aangebroken dat het immens complexe Go-spel, met meer mogelijke stellingen dan atomen in 't zichtbare heelal, volledig doorgrond, begrepen en opgelost is en ons geen nieuwe uitdagingen meer kan bieden? Dat we wellicht beter op zoek gaan naar een andere hobby en ons vanaf vandaag maar moeten gaan verdiepen in de Japanse Bloemschikkunst Ikebana?
AlphaGo in een Notendop
AlphaGo is gebaseerd op een vorm van kunstmatige intelligentie genaamd Deep Learning. Kortweg bestaat deze techniek uit het efficiënt leren van verbanden en patronen uit een giga hoop gegevens. Hiervoor worden verschillende complexe lagen van lerende algorithmes (neurale netwerken) gebruikt. Zo kan een neuraal netwerk na uitgebreide training bijvoorbeeld gezichten op foto's herkennen of gesproken zinnen correct vertalen. Eenmaal fit kan het getrainde systeem ook soortgelijke en onbekende verbanden en patronen in nieuwe data proberen te vinden.
Het bijzondere en grensverleggende van AlphaGo op AI gebied is de unieke manier waarop het programma met zeer uitgebreide en diepgaande training geleerd heeft Go-posities en patronen te herkennen en interpreteren. Hiervoor heeft het onder meer 30 miljoen posities uit partijen van de KGS Go Server beoordeeld (met een 13-laags neuraal netwerk). Iedere laag van het netwerk krijgt daarbij een eigen taak, bijvoorbeeld het bijhouden van het aantal vrijheden. Door terugkoppeling van het eindresultaat van de partij met iedere positie heeft AlphaGo geleerd kansrijke zetten slim en efficiënt te selecteren (zie Fig. 1).
Dit leerprincipe is eigenlijk heel simpel en lijkt sterk op zoals we zelf ook Go leren: naarmate je meer en meer speelt geef je steeds meer waarde en voorkeur aan die zetten die in eerdere partijen succes en winst opleverden. Na training lukte het AlphaGo om 57% van de zetten van de Go-profs succesvol te reproduceren. Daarbij werd ook duidelijk dat met kleine verbeteringen in deze nauwkeurigheid onmiddelijk grote sprongen voorwaarts in speelsterkte bereikt kunnen worden.
Met dit basis leerproces van AlphaGo is echter nog weinig nieuws onder de horizon: als je te lang doorgaat met trainen op deze manier ga je je teveel focussen op bepaalde voorkeurszetten die vaak in de bestudeerde partijen voorkomen. Het nadeel daarvan is dat je dan minder oog hebt voor andere, wellicht betere en meer kansrijke zetten voor winst.
Om dit tegen te gaan trainde een al wat volwassen versie van AlphaGo tegen willekeurig één van zijn jongere, minder wijze voorgangers. Na het spelen van telkens 64000 partijen werd de verbeterde speelwijze van de meest volwassen AlphaGo teruggekoppeld door toevoeging aan zijn eigen groep tegenstanders. Vanaf daar kon het proces dan weer van voor af aan beginnen. Zo werden er na 20 iteraties in totaal bijna 1.3 miljoen Go-partijen gespeeld. Effectief werd het programma dus steeds sterker door veel tegen zichzelf te spelen.

Fig. 1 Door het, na uitgebreide training, slim beperken en selecteren van goede vervolgzetten hoeft AlphaGo, van alle mogelijke legale zetten in een positie slechts nog maar enkele zetten goed door te rekenen (rood). Uit deze kleine groep mogelijke voorkeurszetten selecteert AlphaGo dan de 'beste' zet die, zowel op de korte als lange termijn, statistisch de grootste kans op het winnen van de partij geeft (groen).
Na deze landurige speelsessie won de weledelgeleerde versie van AlphaGo meer dan 80% van zijn partijen tegen eerdere versies. En ook ruim 85% tegen het sterkste open source Go programma Pachi dat op dit moment als 2d amateur op KGS speelt en ~100 000 vervolg simulaties per zet berekent. Na deze trainingstage was AlphaGo in staat objectief, snel, efficiënt en nauwkeurig zetten te selecteren met een hoge winstkans (vervolgzet versie).
Vervolg Spier Training
Beide voorgaande stappen waren vooral gericht op het handig selecteren van die zetten die een hoge kans op winst bieden. Maar wat als je nu in een specifieke Go-stelling grofweg wilt weten wat je kans is om een partij te winnen? Dan zou je eigenlijk alle kansrijke vervolgen moeten uitspelen en kijken welk gedeelte daarvan winst oplevert. En aangezien dat iedere keer weer mega veel rekentijd kost, trainde AlphaGo verder om dit nauwkeurig maar vooral heel snel te kunnen doen.
Bij deze laatste training van AlphaGo bleek het ook nu weer belangrijk om proberen te generalizeren naar nieuwe posities, in plaats van teveel te leunen op al eerder voorbij gekomen en bestudeerde Go-stellingen. Daartoe speelde de volwassen versie van AlphaGo opnieuw tegen zichzelf om zo 30 miljoen posities te genereren waarbij voor iedere positie afzonderlijk de kans op het winnen van de partij werd berekend. Deze versie van AlphaGo is dus vooral gericht op het snel evalueren van de stelling (evaluatie versie).
Elk van deze versies van AlphaGo kun je een behoorlijke Go-partij laten spelen op top amateur niveau. Tegelijkertijd kun je je voorstellen dat de vervolgzet versie teveel nadruk gaat leggen op de beste zet in een bepaalde stelling terwijl de evaluatie versie voornamelijk bezig zal zijn met of een zet uiteindelijk partijwinst oplevert. En dat geeft soms heel verschillende zetten tussen deze versies (vergelijk op de korte vs. lange termijn).
Het doordachte aan AlphaGo is nu het voor de eerste keer efficiënt combineren van neurale netwerken, zowel voor het genereren van vervolgzetten als het nauwkeurig en snel evalueren van posities, met precieze doorrekening middels Monte Carlo Tree Search. MCTS op zichzelf was tot nu toe de meest toegepaste techniek bij Go-programma's maar bleek vaak te rekenintensief en onnauwkeurig om gelijk-op van een Go-prof te kunnen winnen. Mede vanwege deze belangrijke nadelen van MCTS werd gedacht dat het nog zeker een jaar of 10 zou duren voordat een computer programma een Go-prof zonder handicap op een 19x19 bord zou kunnen verslaan.
Eerste partij Fan Hui (B) tegen AlphaGo
Tijdens het naspelen van de eerste partij van de match (zie Fig. 2, Fan Hui is zwart) bekruipt je een vreemd gevoel: de zetten van AlphaGo zijn kraakhelder, logisch onderbouwd en voelen als van een tegenstander die bereid is om voor iedere millimeter keihard te knokken en een oersterke wil heeft om te winnen. Die sluw rekening houdt met initiatief, urgentie en grootte van de zetten.
De eerste echt opmerkelijke zet van AlphaGo daarbij geeft zowel lucht als invloedpotentieel aan zijn witte, beetje in de ruimte hangende groep en voorkomt tegelijkertijd dat zwart met een eventuele aanvalszet punten in sente kan binnenhalen (driehoek).
Met de laatste zet in het diagram (cirkel) knipt AlphaGo twee stenen af, verhoogt daarmee sterk de druk op zwart en neemt 't initiatief. Na grof tellen heeft wit redelijke kansen om de partij te winnen (komi is 7.5). Uiteindelijk zal AlphaGo de partij nipt met 2.5 punt winnen en Fan Hui ongetwijfeld verwonderd en onthutst achterlaten. Bijzonder schrale troost dat Fan Hui nog wel twee van zijn vijf snelle, informele partijen (met 3x30s byoyomi bedenktijd) tegen AlphaGo wist te winnen.
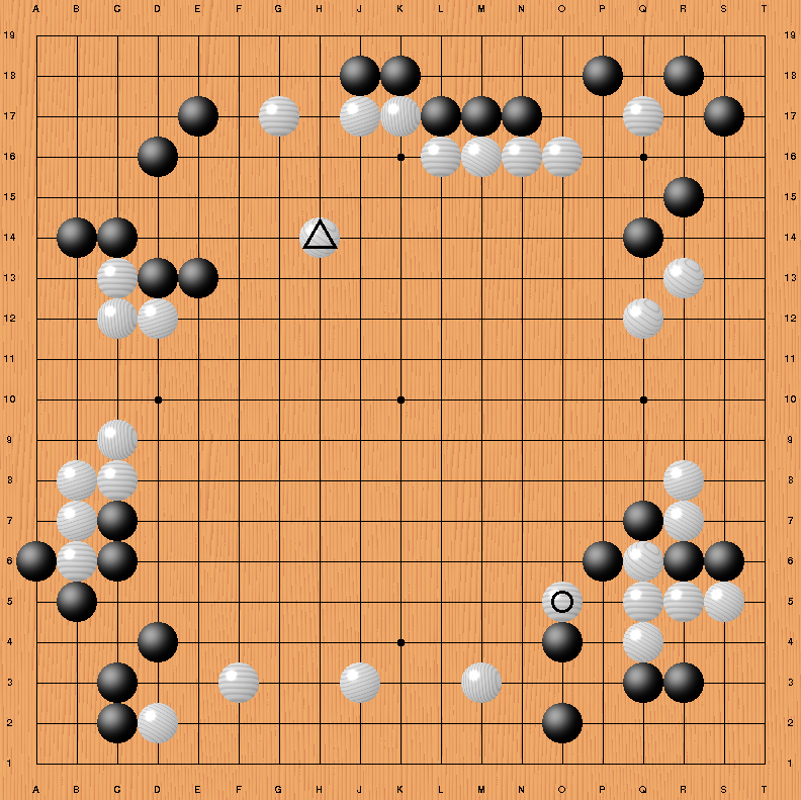
Fig. 2 Bord-positie na zet 62 (cirkel) uit de eerste partij tussen Fan Hui (B) en AlphaGo. De steen gemarkeerd met een driehoek (zet 58) is een voorbeeld van de slimme zetkeuze algorithmes van AlphaGo.
De meest opvallende dingen waarmee AlphaGo rekening houdt bij het beoordelen van een stelling zijn of een zet ergens op het bord een succesvolle ladderbreker is, hoeveel vrijheden er onstaan na het spelen van een zet, hoeveel stenen van de tegenpartij (of van zichzelf) kunnen worden geslagen en of een zet niet de eigen ogen opvult. Helemaal niets dus over wáár je op het bord het snelst gebied kan maken, hoe je een moyo opbouwt (of opblaast), wanneer je omsingeld of verpulverd dreigt te worden of hoe je handig met één zet meerdere vliegen in één klap mept.
Bij de werking van AlphaGo komt merkwaardig genoeg dus weinig echte strategie om de hoek kijken. Zonder de giga hoeveelheid prof partijen en partijen tegen zichzelf zou het programma gewoonweg geen flauw benul hebben waar het moest spelen (of eerst vele, ellenlange zettenreeksen moeten doorrekenen om te bepalen welke zetten in aanmerking zouden komen).
Speelsterkte van AlphaGo
Ondanks de zoveel grotere complexiteit van Go ten opzichte van schaken heeft AlphaGo gedurende de match tegen Fan Hui duizenden malen minder posities bekeken dan bijvoorbeeld Deep Blue tijdens de schaakmatch tegen Kasparov. Dat komt omdat AlphaGo zich, met de enorme spierballen training, in een Go-stelling op een heel slimme en efficiënte manier beperkt tot slechts een zeer kleine selectie van 'beste' zetten. En alleen die zetten hoeven dan nog verder te worden doorgerekend en geëvalueerd. Al met al dus sterk lijkend op de manier waarop wij zelf proberen de 'beste' zet te vinden in een Go-partij.
Bij een internationaal computer-Go tournooi (met 5 sec rekentijd per zet) is AlphaGo ook uitgekomen tegen de op dit moment sterkste commerciële Go-programma's Crazy Stone en Zen, en sterkste open source programma's Pachi en Fuego. Deze programma's zijn allemaal gebaseerd op de meest efficiënte MCTS systemen. Van de 495 gespeelde partijen won AlphaGo er 494. Om het spannender te maken speelden de andere programma's vervolgens partijen met vier stenen voorgift tegen AlphaGo. Ook daarvan wist AlphaGo er meer dan 77% te winnen (zelfs 100% in het geval van de versie van AlphaGo die draaide op meerdere computers). AlphaGo blijkt dus vele dan graden sterker dan alle andere voorgaande Go-programma's.
In vergelijking met de traditionele MCTS gebaseerde Go-programma's, gebruiken de neurale netwerken van AlphaGo, voor zettenkeuze en bordevaluatie, ordes van grootte meer rekenkracht. Om deze neurale netwerken efficiënt te kunnen combineren met MCTS gebruikt AlphaGo daarom asynchrone (multi-thread) zoek opdrachten die simulaties doorrekenen op conventionele CPUs en gelijktijdig zettenkeuze en evalutie netwerken doorrekenen op grafische processors. Zo speelt de één-machine versie van AlphaGo met 48 CPUs en 8 grafische processors aan rekenkracht en bereikt daarmee een sterkte van ~2d prof.
Om AlphaGo nog meer power te geven ontwikkelden de mensen achter DeepMind ook een versie die op meerdere computers tegelijk draait. Deze versie is ook de daadwerkelijke versie van AlphaGo die Fan Hui met 5 – 0 heeft weten te verslaan. En daarvoor gebruikte AlphaGo 1202 CPUs en 176 grafische processors met volgens DeepMind een sterkte van ongeveer 5d prof.
Nabije Toekomst
In een tweet maakte Demis Hassabis, hoofd en mede-oprichter van Google's DeepMind, op 4 Februari bekend dat AlphaGo komende 9-15 Maart speelt tegen de sterkste Go-prof ter wereld: Lee Sedol (9p). De match van 5 partijen wordt live op You Tube uitgezonden en zal gespeeld worden in Seoul, Zuid Korea. In een eerste reactie zei Lee Sedol: 'hoewel AlphaGo een sterke Go-speler lijkt te zijn, ben ik er zeker van dat ik de match kan winnen'. De winnaar ontvangt 1 miljoen dollar.
Hassabis maakte tegelijkertijd bekend: 'als AlphaGo de match tegen Lee Sedol wint, de grootste speler van het afgelopen decennium, dan denk ik dat dat zou betekenen dat AlphaGo beter zou zijn in het spelen van Go dan wie dan ook ter wereld'.
Afhankelijk van de doorontwikkeling van AlphaGo gedurende de afgelopen maanden en de hoeveelheid computers en grafische processors die het DeepMind team wil inzetten tijdens de komende match, zal de sterkte van AlphaGo redelijk in de buurt van Lee Sedol kunnen komen. De kans is daarmee groot dat dit een enorm spannende match gaat worden (mogelijke aanpassingen in AlphaGo specifiek toegespitst op de speelstijl van Lee Sedol even buiten beschouwing gelaten). Als AlphaGo de match van Lee Sedol mocht winnen dan is dat ongetwijfeld een véél grotere sensatie en spektakel dan toen Deep Blue van Kasparov won.
Ten opzichte van Fan Hui heeft Lee Sedol, naast zijn sterkte, nóg een belangrijk voordeel: hij weet tenminste wat hij kan verwachten van AlphaGo. Denkelijk lukt het Lee Sedol alleen al daarom om minimaal één van zijn 5 formele partijen tegen AlphaGo te winnen. Maar het zou niet verbazen als Lee Sedol de match tegen AlphaGo wint met 3-2 (of 4-1). En als je daarom wilt wedden … Deep Learning modellen zijn zo goed als de data die je ze voedt.
Tenslotte
Wanneer de tijd gaat komen dat Go-programma's als AlphaGo louter met geniale zetten komen en bovenmenselijk presteren zodat Lee Sedol zelfs met negen stenen voorgift niet meer van ze kan winnen?
Zonder ook maar enige afbreuk te willen doen aan de enorm waardevolle ontwikkeling en knappe prestaties van AlphaGo: in de basis kan het programma weinig meer dan zich baseren op een giga geheugen vol eerdere, door Go-profs gespeelde partijen.
Sneller en nauwkeuriger zetten doorrekenen dan wij zelf kan AlphaGo vast en zeker al maar of AlphaGo ook binnenkort --zelf-- tot nieuwe, creatieve en prachtig abstracte zetten kan komen, die in één klap de 'Go-flow' van de rivier sneller door het landschap laten meanderen?
copyright: Bob van den Hoek, 8 Febr. 2016
vragen en info kunnen ook naar: bobvdhoek@simupro.nl
Links
Silver, D. en 19 auteurs, Nature, Vol 529, 28 Jan. 2016
Tijdschrift 'GO', jaargang 38, nr 1
Neural Computing “An Introduction” R Beale & T Jackson 1990, Institute of Physics Publishing UK
Alpha houdt niet eens vrijheden bij! (Peter Dijkema)
ReplyDeleteGewoon wauw! Wat een tijd om te bestaan!
ReplyDelete