Deep Learning program AlphaGo was developed by the Google DeepMind team specifically to play the board game Go. DeepMind was founded in London in 2010 by Demis Hassabis, Shane Legg and Mustafa Suleyman. The mission of DeepMind is to solve intelligence and use it to make the world a better place (as a real advertisement slogan). DeepMind was at the time supported by the most iconic tech entrepreneurs and investors who had a clear-cut vision of the future, prior to being acquired by Google early 2014: their biggest European acquisition ever of $400 million.

In this blog, an overview is given of the different AI components of AlphaGo as well as details about the teaching material, learning methods and skills of the program. In the first part (Under a small magnifying glass), the most important neural network components are put to spotlight along with their goal and function as part of AlphaGo. In the second part (Under a large magnifying glass), the characteristics of convolutional neural networks that AlphaGo is based on are covered in more detail.
Together, these two parts provide a basic overview of how the AI program is able to play go with such an unprecedented, never shown before achievement and extraordinary tour de force performance that amazingly and phenomenally are way beyond the original data (strong amateur games) from which AlphaGo has learned.
Under a small magnifying glass
AlphaGo is based on a branch of artificial intelligence named Deep Learning. In brief, this is a technique for efficiently learning associations and patterns from a giga amount of data. To this end, different complex layers of self-learning algorithms (neural networks) are used. After extended training, for instance, a neural network can learn to recognize faces in images or translate spoken sentences correctly. Once fit, the trained system is also able to find similar and unknown associations and patterns in new data.
The special and ground-breaking that sets apart AlphaGo in the area of AI, is the unique manner, with very extensive and in-depth training, in which the program has learned to recognize and interpret go-positions and patterns. For this purpose AlphaGo judged, among other things, 30 million positions from 130,000 games from the KGS Go Server (with a 13-layer neural network). Each layer of the network has thereby its own task, for instance to keep track of the number of liberties. By back propagation of the end result of the game to every position, AlphaGo has learned to select likely winning moves in a smart and efficient manner.
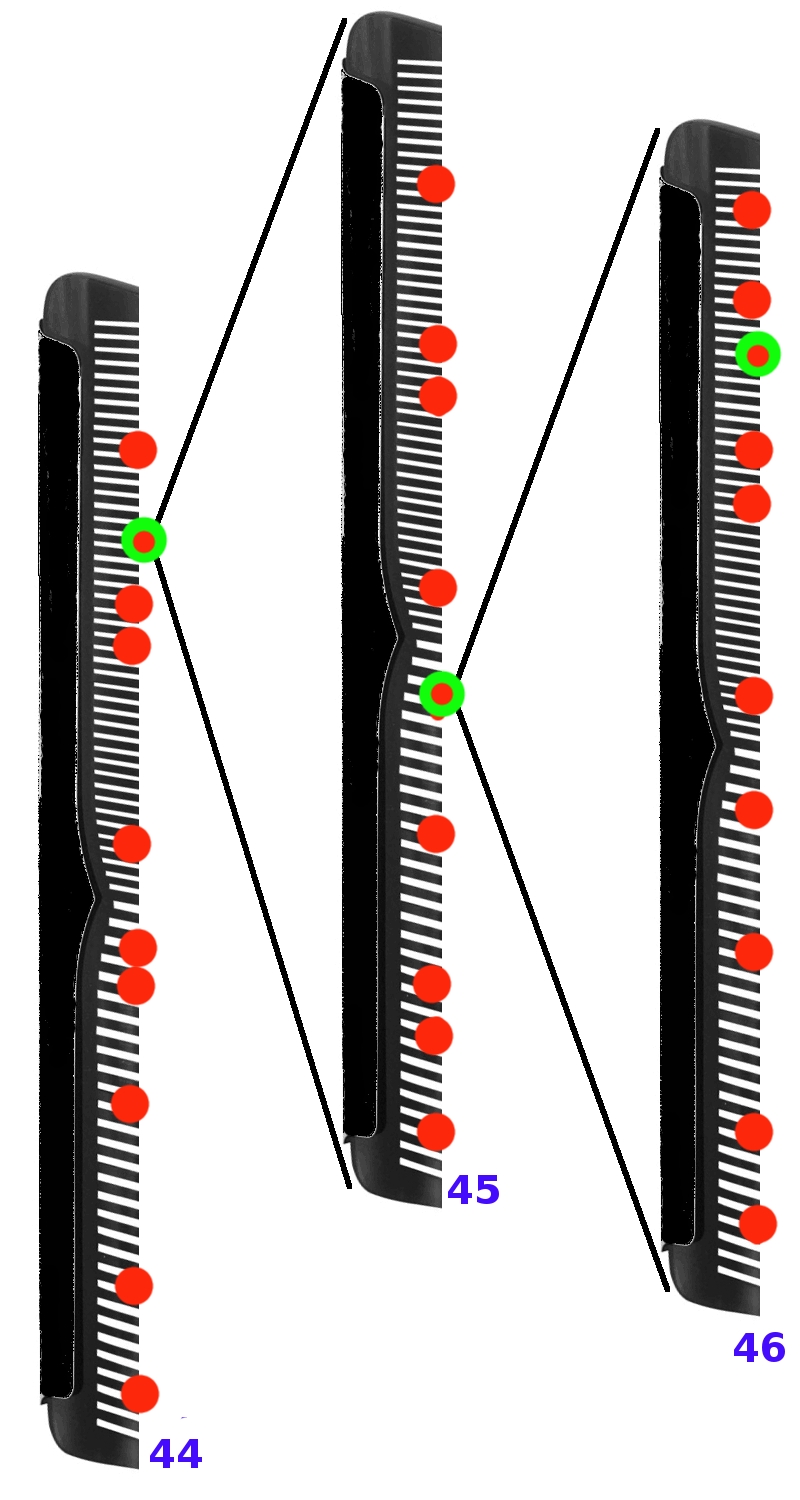
By smart restriction and selection (after extensive training) of good follow-up moves from all legal moves in a position, AlphaGo only needs to calculate a few moves thoroughly (red). From this small group of preferred moves, AlphaGo then selects the 'best' move that statistically, both on the short and long run, provides the highest probability of winning the game (green).
This learning process basically is very simple and rather similar to the way we learn Go ourselves: as you play more and more you give increasingly added value and preference to moves that produced success and benefit in earlier games. After training, AlphaGo managed to reproduce successfully 57% of the moves from the go-profs. During this process it became also clear that with small improvements in this accuracy immediately great leaps forwards can be achieved in playing strength (basic policy version).
Using the basic policy version, an analogue version is made which enables AlphaGo to come up very rapidly with a next 'best' move, though less accurately. To this end, the program used ~140,000 patterns to determine efficiently and quickly probable good follup-moves in a go-position containing one or more of these patterns. After extensive training, this version of AlphaGo succeeds, about 1000 times faster than the basic version, to reproduce about 24% of the moves played by go-profs (fast policy version).
With this basic learning process of AlphaGo, however, there is little news under the horizon yet: if you continue training for too long in this manner, you will be focusing too much on certain preferred moves that just occur frequently in the games studied (so called overfitting). This has the disadvantage that you might ignore other, relatively rare but perhaps better and more likely winning moves.
To prevent this, a more mature version of AlphaGo trained against one of it's randomly selected younger, less wise predecessor program versions. After playing repeatedly 64,000 games in this manner, the most mature AlphaGo was added to it's own group of opponents. From that point, the entire process was started all over again. In this manner, in total ~1.3 million go-games were played after 20 iterations. Effectively, the program did become increasingly stronger by playing many games against itself (improved policy version, also: 'reinforcement learning policy').
After this long-term play-session the final honorary version of AlphaGo won more than 80% of the games against it's predecessors. And also over 85% against the strongest open source go-program Pachi which currently plays as 2d amateur on KGS and computes ~100,000 follow-up simulations per move. After this boot camp AlphaGo was able to select positional moves with a high probability of winning in an objective, fast, efficient, and accurate way.

Another example of AlphaGo's policy version: in every goposition all possible legal moves are considered. With long-lasting training AlphaGo has learned to select moves that provide the highest probability of winning the game. And from this selection, AlphaGo chooses the move that is recommended most by it's various algorithms.
Both preceding stages focused in particular on smart selection of moves with a high probability of winning. But what if you would like to know your chances of winning the game in a specific go-position? Then you actually would have to play out all promising follow-up moves and determine what fraction of those moves would result in a win. Since this, over and over again, consumes a mega amount of computing time, AlphaGo was trained further to be able to do this accurately but above all in a very fast and efficient way.
With this final training phase AlphaGo builds --for each go-position to be judged-- a complete collection of games by rapidly playing moves, that are at random at first sight, until the game has finished in order to see who ultimately will win. In practice, these moves are not at all random because the program smartly uses the fast policy version ('policy network') to determine in a very restrictive way which moves provide the highest probability of winning. To use the basic (or improved) policy version for this purpose, it would just take by far too much computing time.
When finishing the game from a given go-position, the fast policy version chooses rapidly the 'best' possible move for both parties. This efficient 'rollout policy' has been built and trained in the same manner as the basic policy version but is specifically designed to be much faster (about 1000x faster).
During this last training phase of AlphaGo, it again turned out to be important to try to generalize to new positions instead of leaning too much on go-positions seen and studied previously. Therefore, the mature version of AlphaGo once more played against itself to generate 30 million positions whereas for each individual position the probability of winning the game was computed. This fourth version of AlphaGo is primarily focused on fast evaluation of the position (evaluation version).
To summarize, in practice there are three versions of the 'policy network' that are identical in architecture but differ significantly in terms of accuracy and speed with which they select the next 'best' move. In contrast, the fourth version is specifically trained to evaluate any board position fast and accurately.
Each of the AlphaGo versions above can play a rather good game of Go on top-amateur level. At the same time, however, you can imagine that the policy version will put too much emphasis on the best move in a specific local position while the evaluation version will be preoccupied with whether a move ultimately leads to winning the game. This sometimes may result in substantially different moves between these versions (compare in the short vs. long run).
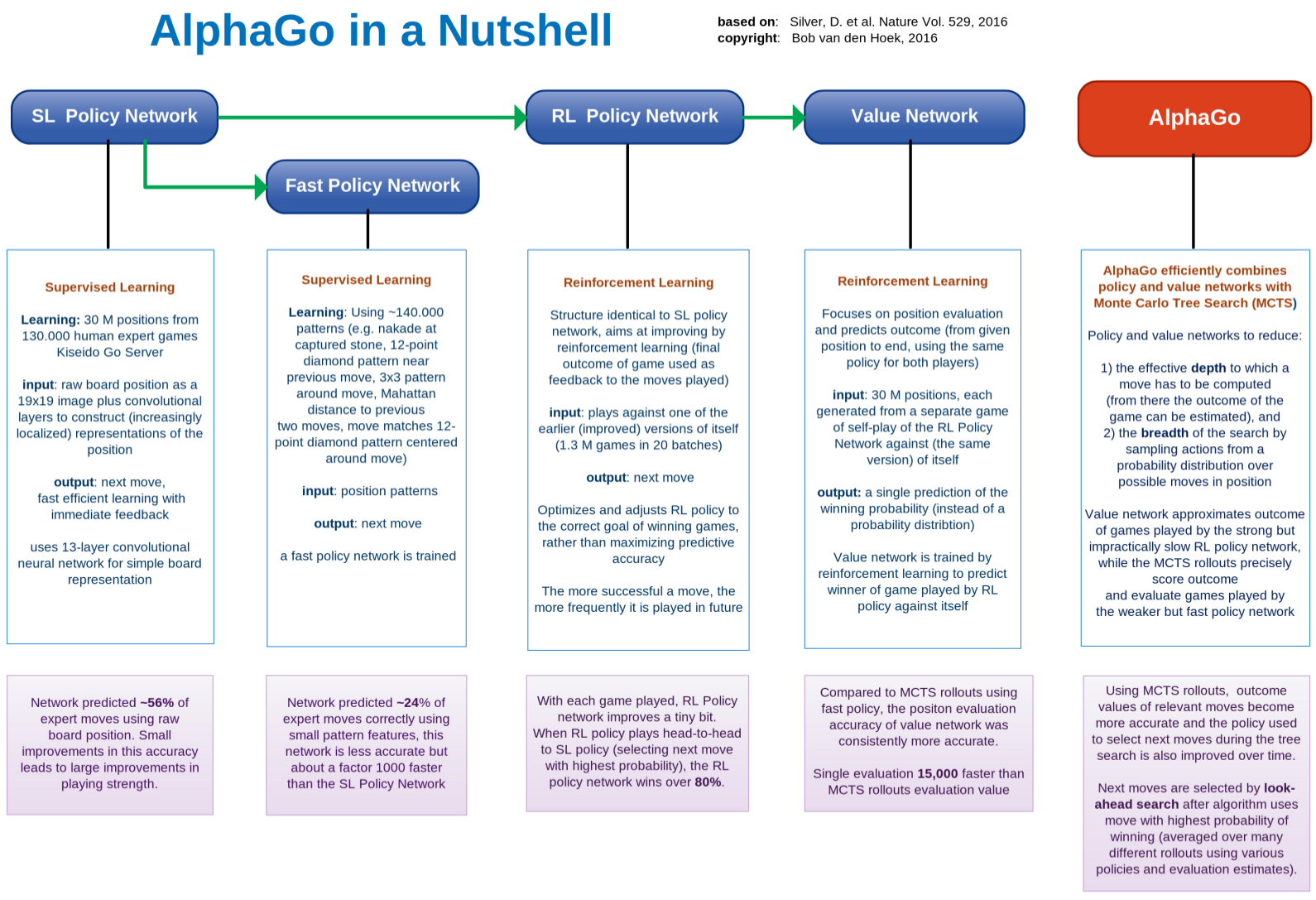
The most deliberate aspect of AlphaGo now is it's ability to combine various neural networks, both to generate good follow-up moves and to evaluate positions efficiently and accurately, for the first time with precise move sequence computation using Monte Carlo Tree Search.
Until now, self-contained MCTS has been one of the most applied techniques to Go programs but often turned out to be too computation intensive and inaccurate to win against a go-professional in an even game. Also, because of these important disadvantages of MCTS, experts thought it would take at least another decade before a computer program would be able to defeat a go-prof in a no-handicap game on a 19x19 board.
Until now, self-contained MCTS has been one of the most applied techniques to Go programs but often turned out to be too computation intensive and inaccurate to win against a go-professional in an even game. Also, because of these important disadvantages of MCTS, experts thought it would take at least another decade before a computer program would be able to defeat a go-prof in a no-handicap game on a 19x19 board.
In conclusion, after extensive deep learning and training by self-playing hundreds of millions of games, AlphaGo's various neural networks versions are applied, in a smart and efficient manner, to restrict the number of good follow-up moves that need to be further evaluated and the depth a move has to be computed deeply. As a consequence, board-positions in a game can be judged rapidly and accurately using a 'policy network' to smart move selection and a 'value network' to compute the probability of winning.
By nifty combination of the three different versions of the 'policy network' (basic, fast, and improved policy versions) with both the 'value network' (evaluation version) and real-time Monte Carlo Tree Search rollout computations, AlphaGo is able to come up with the 'best' move that provides the highest probability of winning the game in an ultra efficient, fast, and reliable manner.
By nifty combination of the three different versions of the 'policy network' (basic, fast, and improved policy versions) with both the 'value network' (evaluation version) and real-time Monte Carlo Tree Search rollout computations, AlphaGo is able to come up with the 'best' move that provides the highest probability of winning the game in an ultra efficient, fast, and reliable manner.
Under a large magnifying glass
AlphaGo is based in principle on general-purpose AI methods. Under the hood, the program uses convolutional (filtering and encryption by transformation) neural networks that attempt to mimic the way of play and the moves of go-experts down to the last detail, and subsequently become stronger by playing giga many games against themselves.
In recent years, deep convolution neural networks (CNN) have achieved unprecedented performance in the fields of image classification and face and location recognition. These networks use many, extended layers of neurons (learning units) to construct autonomously increasingly abstract, very local and detailed representations of an image (without the necessity of having to hold the network's hand continuously).
Moreover, every network layer acts as a filter for the presence of specific features or patterns. For detection by such a filter it is irrelevant where exactly in the original image a specific feature or pattern is present: the filters are especially designed to detect whether or not the image does contain any such characteristics. The filter is shifted multiple times and applied at different image positions until the entire image has been covered in detail (the filter can correct, if necessary, e.g. for scale, translation, rotation angle, color, transformation, opacity, out of focus, deviations of specific features present in the original image).
Actually, the DeepMind team has employed a network architecture similar to convoluational neural nets when designing AlphaGo. Herewith, the board-position is represented by an image of 19x19 board points and offered as input after which the convolutional network layers subsequently construct a handy, compact, and precise representation of that position. Next, these layers can actually function as powerful filters in every go-position, for any specific pattern (or feature of the position) you want to detect locally and, for instance, be used for detailed classification, analysis or review of the board-position.
When processing increasingly smaller portions of the go-position image, the specific features of each network layer can be combined in order to distill an increasingly detailed and distinctive representation of the original go-position.
By repeating this process, very specific and detailed features can be used for classification of a go-position (such as eye shape or number of liberties) in order to assign the position to multiple, ultra specific categories extremely accurately.
In practice, the special and incredible power of a convolutional network is that, by smart combination of different feature (filter) maps, a go-position can be categorized and reviewed very specifically on the basis of hundreds (if not thousands) of features and patterns simultaneously. In this manner, any go-position can be classified ultra fast and precise by first crude and clever characterization in terms of e.g. influence, corner fight, life-and-death problem, and then detailed designation of increasingly smaller characteristics of the position.
An important advantage of such convolutional networks is their almost complete independence on any prior knowledge and/or human feature design efforts in order to ultimately learn and assign tens of thousands, ultra-detailed features of a go-position. Such networks require relatively little pre-processing of an input board-position: the network is perfectly able to learn (sometimes millions of) these ultra-distinctive feature filters entirely by itself, autonomously.
Each layer of the network has thereby its own task of detecting some in advance, handcrafted features of the position, for instance to keep track of the number of liberties (atari), ladders, or a 'pattern book' of all possible 3x3 patterns. By back-propagation of the end result of the game to each position, AlphaGo has learned to assign win potentials to every possible move in a position and to select promising moves in a fast and efficient manner (see above: Under a small magnifying glass).
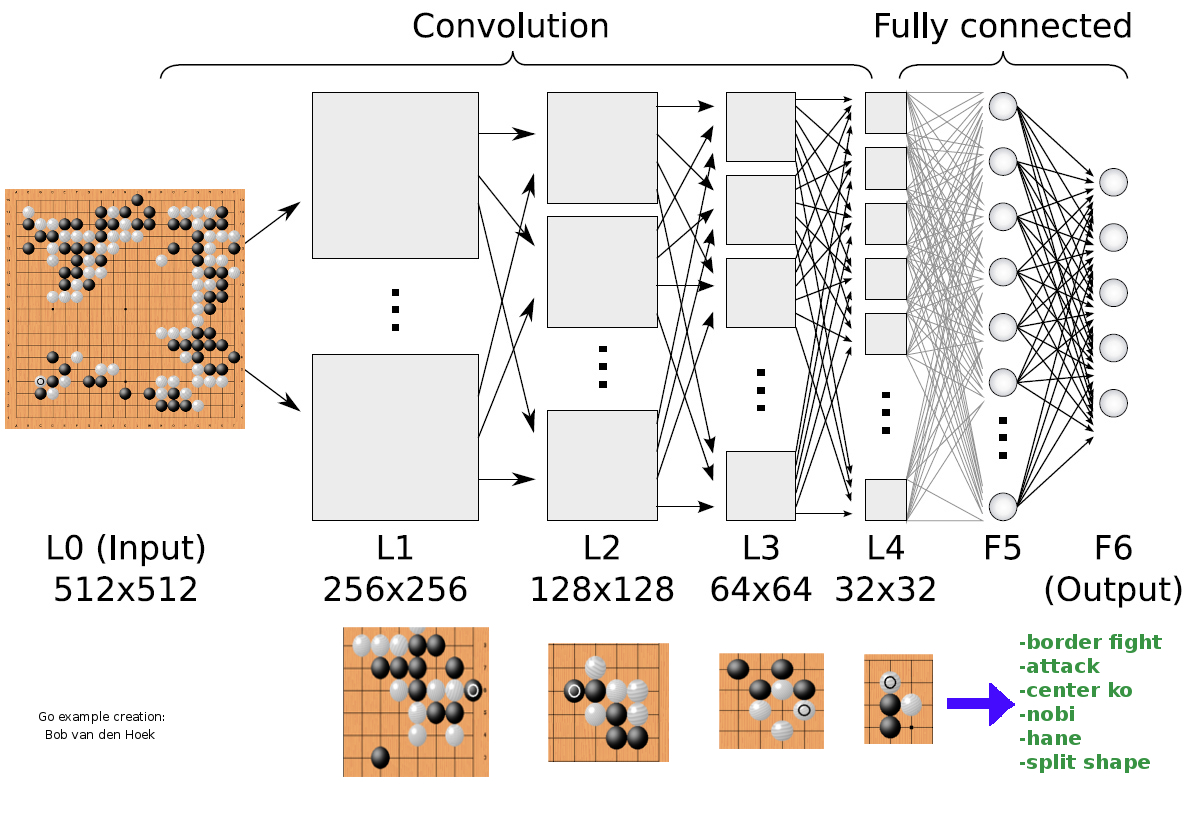
The schematic image above shows a rather simplified example of the architecture of a convolutional neural network (just six layers) that contains characteristic components of the underlying architecture as has been applied to AlphaGo. In reality, the number of network layers, input dimensions and specific features for each layer as used in AlphaGo are much more complex than is shown here.
Schematically, this image just illustrates the basic ingredients and function of the convolutional neural networks of AlphaGo: in a nutshell, the various layers convolve (filtering and encryption by transformation) the original 19 x 19 go-position by detection of increaslingly smaller and more abstract go-features.
In the example diagram, the go-position may be classified by the network as: border fight, attack, center ko, nobi, split move. In practice, the end classification by a convolutional network may contain sometimes thousands (or even tens of thousands) filters and features that may be present in the original data, such as the go-position in this example.
Schematically, this image just illustrates the basic ingredients and function of the convolutional neural networks of AlphaGo: in a nutshell, the various layers convolve (filtering and encryption by transformation) the original 19 x 19 go-position by detection of increaslingly smaller and more abstract go-features.
In the example diagram, the go-position may be classified by the network as: border fight, attack, center ko, nobi, split move. In practice, the end classification by a convolutional network may contain sometimes thousands (or even tens of thousands) filters and features that may be present in the original data, such as the go-position in this example.
Both neural networks have as input 48 feature planes of the 19 x 19 board-points image (which in this diagram are represented by just one single image) and are configured specifically to optimize the efficiency and accuracy of their task. The 'policy' network of AlphaGo during the Fan Hui match used 13 layers and 192 filters, the 'value' network 15 layers (whereas layers 2 - 11 are identical to those of the 'policy' network).
With the last layer, the convolutional network classifies the go-position by a precise combination of all specific go-features detected. In exactly the same manner, new and never seen before go-positions can be recognized and classified accurately after the deep learning neural network has been trained thoroughly.
Where a human is able to play at most 10,000 serious games in a lifetime, AlphaGo plays hundreds of millions of games in a couple of months: training a new version of AlphaGo from scratch just takes about 4 – 6 weeks. Thereafter, a phenomenally, power-trained AlphaGo is able to compute and judge accurately tens of thousands go-positions per second (for the distributed version of AlphaGo running on multiple, first-class computers).
[Part 3: Lee Sedol about the Go board in his head]
In this blog, an overview is given of the different AI components of AlphaGo as well as details about the teaching material, learning methods and skills of the program.
ReplyDeleteIn the first part (Under a small magnifying glass), the most important neural network components are put to spotlight along with their goal and function as part of AlphaGo. In the second part (Under a large magnifying glass), the characteristics of convolutional neural networks that AlphaGo is based on are covered in more detail.
Hi Bob,
ReplyDeleteIs that correct the shape of the weights in L1, L2 and L3 in the last figure(above)?
Thnaks
The dimensions and shape of the L1, L2 L3 in the figure shown are just a very simple example of the architecture of a convolutional neural network, analogue to the network architecture as applied to AlphaGo. However, the dimensions and shapes shown are not as have been used for AlphaGo (starting with 48 feature planes of 19x19 images).
DeleteHey there,
ReplyDeletethe last graphic is a bit confusing to me. The game-patterns that are displayed below the convolutional layers range from large patterns near the input to smaller, more detailled ones near the output. Shouldn't this be the other way round?
I do agree that convolutional layers farther away from the input usually have smaller feature maps, as depicted in the graphic. However, am I wrong in believing that their neurons' inputs essentially depend on larger parts of the image? Aren't the very local features, like the GO-pattern on the lower right, being detected by the first convolutional layer and the rather large features, like the one on the left, being detected by layers to the right, since they process information about the presence of local features?
Maybe I just interpreted the graphic the wrong way or I am making another mistake. Hope you can clear up my confusion.
Kind regards,
Kieron