[NL Versie]
For the first time during this five-game match, Lee Sedol was able to take a clear lead after a brilliant move in the second half of the middle game, fighting hard to prevent AlphaGo from making (potential) territory in the center.
Even though Lee Sedol played under ultra-high pressure for more than an hour, using his last byo-yomi period up to the max each move (maximum of 1 minute per move), he was able to maintain his built up advantage until far in the endgame of this fourth game of the match. Finally, AlphaGo resigned after playing a handful of doubtful moves and several mistakes that even lost additional points.

Top Go-prof Gu Li (9p) described Lee Sedol's move 78 (triangle, Lee Sedol is white) in the fourth game of the match against AlphaGo as a "God's move". Another Go pro commented after Lee Sedol winning this fourth game: "Lee Sedol just fought the 1000 years history of Baduk".
The way AlphaGo chooses it's next moves on maximizing it's probability of winning (instead of maximizing the difference by which it may win) forces AlphaGo apparently to play suboptimal and perhaps even faulty moves when it's probability of winning the game is falling below a specific threshold (e.g. 50 %).
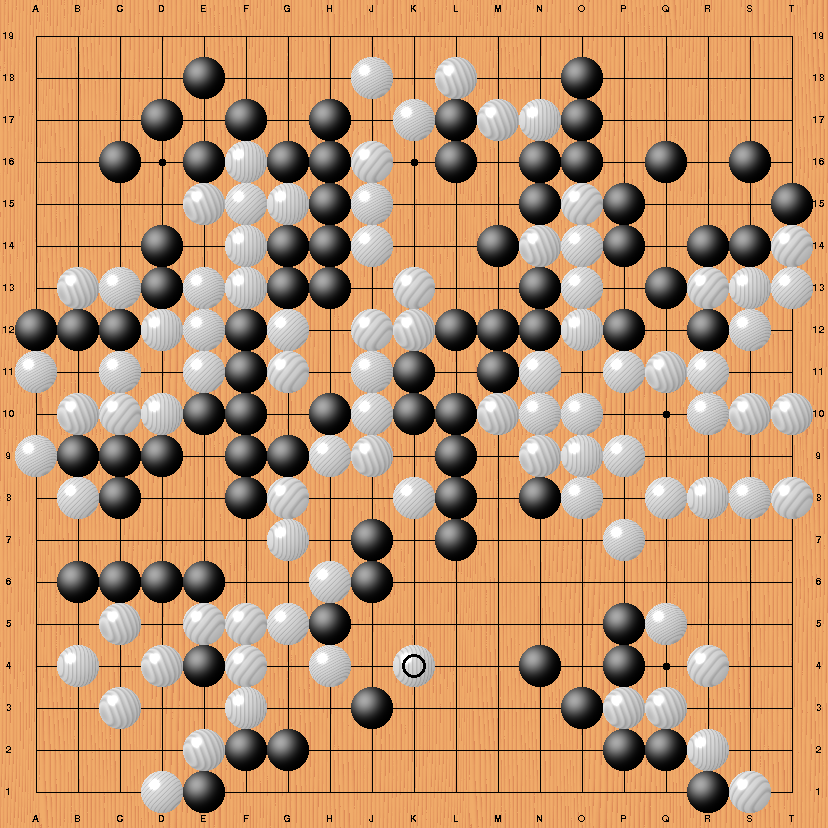
This is the final position of game 4 after Lee Sedol's move 180 (circle), the point in the game at which AlphaGo resigned after it's notion that the probabilities of winning this game were falling below it's critical threshold for resignation. At this point, AlphaGo is behind at least 5 points (komi included) and therefore needs to make more than ~20 points in the bottom center area (without Lee Sedol getting any compensation for that) in order to catch up.
When AlphaGo's awareness of being defeated by Lee Sedol was passed to Google DeepMind's team member and operator Aja Huang (6d amateur), he placed two stones on the board to let Lee Sedol and the world know that AlphaGo resigned and for the first time lost a game (in the official match games without handicap) against a top professional Go player.
This time, Lee Sedol was able to exploit a sequence mistake fighting AlphaGo while the program was misjudging an important middle game fight and lost a heavy group of stones. In return, AlphaGo just got a pover and rather modest sente move. Commentator Michael Redmond (9p) showed several sequences that AlphaGo could have played instead, which would probably have resulted in a considerable better outcome of this fight for AlphaGo.
Lee Sedol's first win against AlphaGo shows --and does prove for the first time-- that deep learning AlphaGo is not playing perfect all the time and really experienced some severe problems in judging correctly the outcome of a rather complex middle-game fight. Even though the fighting in this game seemed not to be as tough as for instance during the second game of the match where ultra-strong AlphaGo defeated Lee Sedol at his own game of fighting play.
After the game Lee Sedol answered a question about his mental condition: "after loosing the first three games and thus the match against AlphaGo, I could not say that there was no psychological shock ... but it was not to the extent that I would have to stop playing the ongoing match because at any moment of the game, I really enjoyed the game. I can tell you that I've not retained any severe damage and I'm very happy to say that I won this single game."
For the first time Lee Sedol has proved that AlphaGo does not play perfect and indeed has some weaknesses in judging and correctly interpreting the outcome of complex middle game fights.
ReplyDelete